Restructuring Decision Tables
Decision tables can be restructured in ways that either join multiple subordinate tables in a single one (“flattening”) or split some table in two (“decomposition”). These operations affect the structure of attributes around the table being restructured.
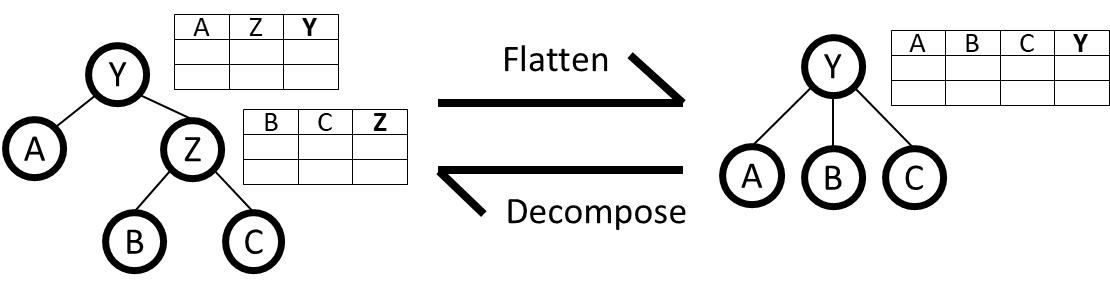
Flatten Decision Tables
Flattening decision tables of some attribute (such as Y in the figure above) considers all subordinate qualitative basic attributes (A, B, C) as inputs of the newly created table. All tables that occur in the subtree are merged in a single table consisting of the inputs and the currently selected root attribute (Y) as the output.
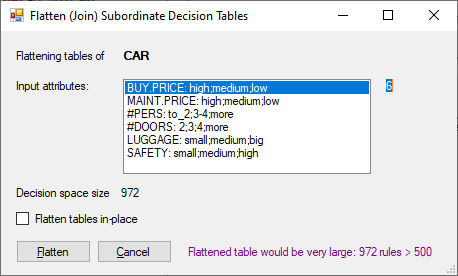
This command first displays a dialogue that shows the list of input attributes and calculates the size of the newly created table. Flattening is not possible if the size exceeds the maximum decision table size (3000). A warning is issued if the resulting table would contain more than 500 rows.
You can also choose whether to:
flatten the tables in-place, replacing the original subtree with the flattened one, or
put the flattened subtree as one of model’s roots, so that you can inspect it and possibly move it to the chosen position.
Decompose Decision Table
Decomposing a decision table means splitting it to two tables, one at the top (Y above) and one subordinate (Z). The subordinate table always combines two of the inputs of the original table (such as B and C above).
In order to make the new subordinate table, a new attribute (Z) has to be constructed, together with its value scale. The top-level table (Y) then combines the new attribute (Z) with the remaining attributes from the original table (A). Only tables having three or more input attributes can be decomposed in this way.
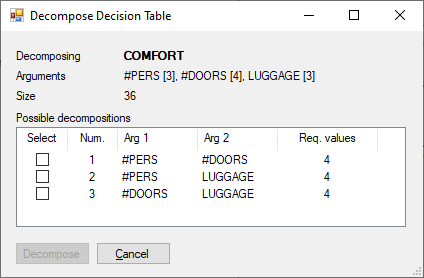
The decomposition command first checks all possible pairs of subordinate attributes. For each pair, it determines the required number of values for the newly created attribute scale so as to accurately represent the original table. To carry out the decomposition, you should choose the most appropriate pair yourself. You should consider:
The number of required values. Typically, a lower number indicates a better split, as it generates smaller decision tables.
The common meaning of the two selected attributes. Typically, they should represent some concept or bear some common meaning, so that you can appropriately name the newly created attribute (Z) after decomposition.
In-place decomposition is not supported. The newly created subtree is inserted at the topmost model level, where you can check it and possibly move to the desired position in the model.